Upload File With Bucket Owner Full Access Control in Python
Unloading into Amazon S3¶
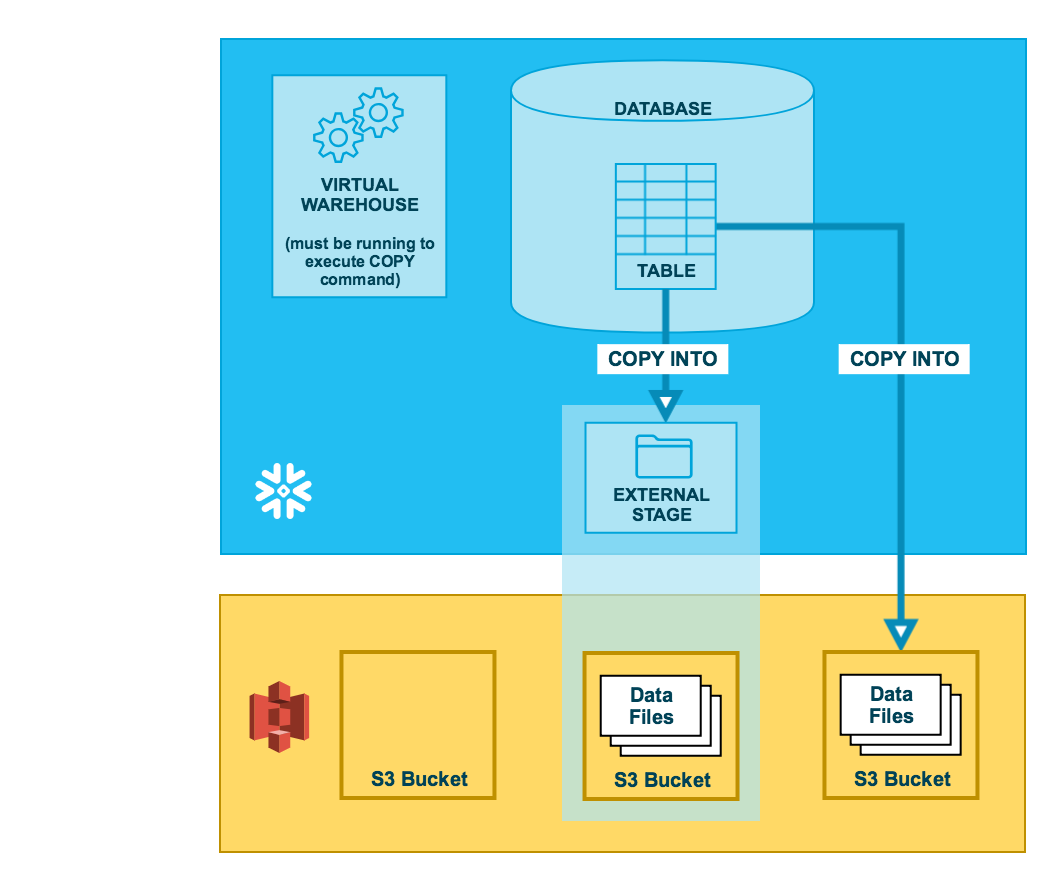
If yous already have a Amazon Spider web Services (AWS) account and use S3 buckets for storing and managing your information files, you can brand use of your existing buckets and binder paths when unloading data from Snowflake tables. This topic describes how to use the Re-create control to unload information from a table into an Amazon S3 bucket. You tin can then download the unloaded data files to your local file arrangement.
Equally illustrated in the diagram below, unloading data to an S3 bucket is performed in 2 steps:
- Step 1
-
Apply the COPY INTO <location> command to copy the data from the Snowflake database tabular array into 1 or more files in an S3 bucket. In the command, you specify a named external stage object that references the S3 saucepan (recommended) or yous can choose to unload directly to the bucket by specifying the URI and either the storage integration or the security credentials (if required) for the bucket.
Regardless of the method you use, this step requires a running, current virtual warehouse for the session. The warehouse provides the compute resources to write rows from the table.
- Step ii
-
Use the interfaces/tools provided by Amazon to download the files from the S3 saucepan.
In this Topic:
-
Assuasive the Virtual Private Cloud IDs
-
Configuring an S3 Bucket for Unloading Information
-
Configuring Support for Amazon S3 Admission Control Lists — Optional
-
Unloading Data into an External Stage
-
Creating a Named Phase
-
Unloading Data to the Named Phase
-
-
Unloading Data Directly into an S3 Bucket
Assuasive the Virtual Private Cloud IDs¶
If an AWS ambassador in your organization has not explicitly granted Snowflake access to your AWS S3 storage account, you tin do and so now. Follow the steps in Allowing the Virtual Private Cloud IDs in the data loading configuration instructions.
Configuring an S3 Bucket for Unloading Data¶
Snowflake requires the following permissions on an S3 bucket and folder to create new files in the binder (and whatsoever sub-folders):
-
s3:DeleteObject -
s3:PutObject
Every bit a best exercise, Snowflake recommends configuring a storage integration object to delegate hallmark responsibleness for external cloud storage to a Snowflake identity and admission management (IAM) entity.
For configuration instructions, see Configuring Secure Admission to Amazon S3.
Configuring Support for Amazon S3 Access Control Lists — Optional¶
Snowflake storage integrations back up AWS admission control lists (ACLs) to grant the bucket possessor full control. Files created in Amazon S3 buckets from unloaded tabular array data are owned by an AWS Identity and Access Management (IAM) role. ACLs support the use case where IAM roles in 1 AWS business relationship are configured to access S3 buckets in 1 or more than other AWS accounts. Without ACL support, users in the bucket-owner accounts could non access the data files unloaded to an external (S3) stage using a storage integration. When users unload Snowflake table data to data files in an external (S3) stage using COPY INTO <location>, the unload operation applies an ACL to the unloaded information files. The information files apply the "s3:x-amz-acl":"saucepan-owner-full-control" privilege to the files, granting the S3 bucket possessor full command over them.
Enable ACL support in the storage integration for an S3 stage via the optional STORAGE_AWS_OBJECT_ACL = 'saucepan-owner-total-control' parameter. A storage integration is a Snowflake object that stores a generated identity and access direction (IAM) user for your S3 deject storage, along with an optional set of allowed or blocked storage locations (i.e. S3 buckets). An AWS ambassador in your organization adds the generated IAM user to the role to grant Snowflake permissions to access specified S3 buckets. This characteristic allows users to avoid supplying credentials when creating stages or loading data. An ambassador can ready the STORAGE_AWS_OBJECT_ACL parameter when creating a storage integration (using CREATE STORAGE INTEGRATION) or afterwards (using ALTER STORAGE INTEGRATION).
Unloading Data into an External Stage¶
External stages are named database objects that provide the greatest degree of flexibility for data unloading. Considering they are database objects, privileges for named stages tin be granted to any function.
You can create an external named stage using either the spider web interface or SQL:
- Spider web Interface
Click on Databases
» <db_name> » Stages
- SQL
CREATE Phase
Creating a Named Stage¶
The following example creates an external stage named my_ext_unload_stage using an S3 saucepan named unload with a binder path named files . The stage accesses the S3 bucket using an existing storage integration named s3_int .
The stage references the named file format object called my_csv_unload_format that was created in Preparing to Unload Data:
CREATE OR Replace Phase my_ext_unload_stage URL = 's3://unload/files/' STORAGE_INTEGRATION = s3_int FILE_FORMAT = my_csv_unload_format ; Unloading Data to the Named Stage¶
-
Use the Copy INTO <location> command to unload data from a table into an S3 bucket using the external phase.
The following instance uses the
my_ext_unload_stagestage to unload all the rows in themytabletable into ane or more files into the S3 bucket. Ad1filename prefix is practical to the files:Copy INTO @ my_ext_unload_stage / d1 from mytable ;
-
Use the S3 panel (or equivalent client application) to retrieve the objects (i.e. files generated by the control) from the bucket.
Unloading Data Direct into an S3 Saucepan¶
-
Use the COPY INTO <location> command to unload data from a table directly into a specified S3 saucepan. This pick works well for advertizing hoc unloading, when you aren't planning regular data unloading with the aforementioned tabular array and bucket parameters.
You must specify the URI for the S3 bucket and the storage integration or credentials for accessing the saucepan in the Re-create command.
The following example unloads all the rows in the
mytabletable into i or more files with the folder path prefixunload/in themybucketS3 bucket:COPY INTO s3 :// mybucket / unload / from mytable storage_integration = s3_int ;
Annotation
In this example, the referenced S3 bucket is accessed using a referenced storage integration named
s3_int. -
Utilise the S3 console (or equivalent client awarding) to retrieve the objects (i.e. files generated by the control) from the saucepan.
Source: https://docs.snowflake.com/en/user-guide/data-unload-s3.html
0 Response to "Upload File With Bucket Owner Full Access Control in Python"
Post a Comment